Enhancing Internet Search with RAG and Open Large Language Models
An internet search tool using Retrieval-Augmented Generation and open-source Large Language Models to answer questions in natural language.
This article introduces an internet search tool based on Retrieval-Augmented Generation (RAG), designed to answer questions posed in natural language. It searches the internet for relevant information and generates concise responses based on the search results.
The tool is designed for local deployment, utilizing smaller open LLMs (specifically Llama3-8B) and a local metasearch engine. This setup eliminates the need for external search-API keys.
The internet search tool is a component of the bot-with-plan project. To dive straight into using the tool, skip ahead to the Usage and examples section or run the accompanying notebook.
Improving Search Accuracy and Relevance with RAG
Answering questions with large language models (LLMs) alone faces two major challenges. First, these models can produce hallucinations, presenting fabricated or inaccurate information as factual. Second, the answers provided by LLMs are constrained by their knowledge cutoff date, meaning they cannot provide information more current than their last update. This results in responses that may not only be outdated but also incorrect. The RAG-based internet search tool is designed to overcome these specific shortcomings. It addresses the issue of outdated knowledge by fetching current and relevant information directly from the internet. Additionally, it mitigates the problem of hallucinations by providing the LLM with factual information, instructing it to extract the most relevant information from the prompt and generate a precise and comprehensive answer.
The search tool utilizes the open-source SearXNG metasearch engine to collect information from multiple internet sources. It uses a reranking model to rank the returned results by relevance, and employs a locally deployed Llama3-8B model to process search results and generate a response. The tool was specifically designed to work with smaller models like Llama3-8B, which has a limited context size of 8192 tokens and fewer capabilities compared to larger open-source models such as Llama3-70B, or commercial models like GPT-4. Instead of passing all the information from an internet search directly to the model for response generation - a strategy suited to larger models - the tool implements multiple pre-processing steps for each search result. It extracts the most relevant information and compiles a single summary for each webpage. This process allows the response generation LLM to focus on the information most relevant to the query and ensures that the context size limit is not exceeded.
The internet search tool can be used either as a standalone tool or by an agent equipped with tool-handling capabilities. This is illustrated in Planner fine-tuning on synthetic agent trajectories where the internet search tool is integrated into an agentic workflow that uses tools, implementing an agentic RAG approach.
Exploring the Internet Search RAG Pipeline
In this section, we will explore the RAG pipeline that powers the internet search, using a practical example to illustrate the process. Let’s consider the following query: “What is the name of the latest NASA rover sent to Mars, when was it launched, and from which location?”
The image below outlines the different stages of the internet search RAG pipeline involved in processing this query:
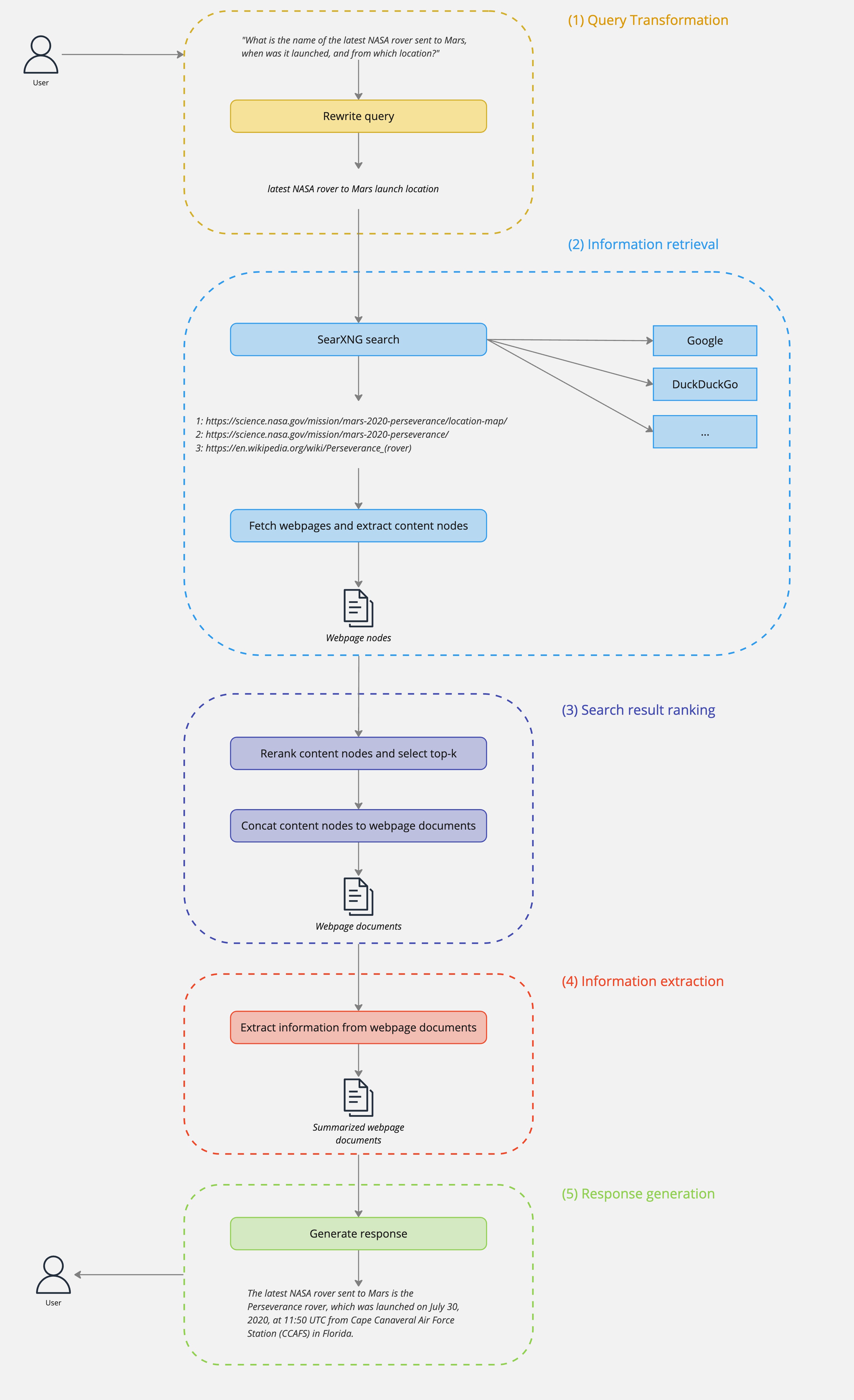
Stage 1: Query Transformation
Queries are typically expressed in natural language and often include extraneous details that might degrade the effectiveness of a search engine. To adress this issue, queries are processed by a LLM-based query rewriter (Llama3-8B). This component filters out irrelevant information and refines the input query into an optimized search query that is better suited for internet search engines.
The query from our example “What is the name of the latest NASA rover sent to Mars, when was it launched, and from which location?” is transformed into the following search query:
1
'latest NASA rover to Mars launch location'
Stage 2: Information Retrieval
After the input query is converted into a search query, it is passed to a local SearXNG meta-search engine. The engine is configured to query a list of search providers, sending the search query to all providers simultaneously. It then collects and aggregates the results into a single ranked list, which includes the URL, title, and a short snippet for each result. This approach allows the system to collect information from a wide range of diverse internet sources.
Note: the current configuration uses a static list of search engines for better reproducibility of search results. This configuration can easily be modified to incorporate additional search providers.
Applying the search query from the previous stage, we retrieve the following search results (only the top 2 results are shown):
1
2
3
4
5
6
7
https://en.wikipedia.org/wiki/Perseverance_(rover)
Title: Perseverance (rover)
Snippet: Perseverance, nicknamed Percy, [2] is a car -sized Mars rover designed to explore the Jezero crater on Mars as part of NASA 's Mars 2020 mission ...
https://science.nasa.gov/mission/mars-2020-perseverance/
Title: Mars 2020: Perseverance Rover
Snippet: Science. The Mars 2020 Perseverance Rover searches for signs of ancient microbial life, to advance NASA's quest to explore the past habitability of Mars ...
The search results returned by SearXNG are ranked and the top-k search results are selected for further processing. The content for these top-k webpages is loaded using the partition_html method of the Unstructured library. This method retrieves the content from a webpage and returns a list of text nodes. Nodes are filtered by type, preferring node types that are more likely to contain relevant information.
The following output shows a sample the nodes (after filtering) from the first URL https://en.wikipedia.org/wiki/Perseverance_(rover). As we can see, not all of these nodes contain information that is relevant to the user request:
1
2
3
4
5
6
7
8
9
(1) NASA Mars rover deployed in 2021
(2) Mars rover designed to explore the
(3) Mars 2020 mission. It was manufactured by the
(4) Jet Propulsion Laboratory and launched on July 30, 2020, at 11:50
(5) Earth days, or 3 years, 3 months and 17 days) since its landing. Following the rover's arrival, NASA named the landing site
...
(40) Associate Administrator of NASA's Science Mission Directorate, Thomas Zurbuchen selected the name Perseverance following a nationwide K-12 student "name the rover" contest that attracted more than 28,000 proposals. A seventh-grade student, Alexander Mather from Lake Braddock Secondary School in Burke, Virginia, submitted the winning entry at the Jet Propulsion Laboratory. In addition to the honor of naming the rover, Mather and his family were invited to NASA's Kennedy Space Center to watch the rover's July 2020 launch from Cape Canaveral Air Force Station (CCAFS) in Florida.
...
(46) The Perseverance rover lifted off successfully on July 30, 2020, at 11:50:00 UTC aboard a United Launch Alliance Atlas V launch vehicle from Space Launch Complex 41, at Cape Canaveral Air Force Station (CCAFS) in Florida.
After completing this stage, we obtain a list of top-k webpages. Each webpage includes a URL, a title, a snippet, and a list of content nodes.
Stage 3: Ranking of Search Results
It is not effective to include all content nodes from the webpages in the response generation step. Many of these nodes may not hold information relevant to the query and could introduce noise that potentially distracts the LLM during response generation. Additionally, using all nodes would increase the overall processing time, as the LLM needs to process a larger number of input tokens. To address these issues, this stage ranks the content nodes of each webpage based on their relevance to the query using a reranking model. This model assigns a relevance score to each content node, reorders the nodes by this score and returns the top-k nodes.
After reranking the content nodes from the previous stage, we identify the the following most relevant nodes:
1
2
3
4
5
Rank: 1 / Score: 0.9879
Associate Administrator of NASA's Science Mission Directorate, Thomas Zurbuchen selected the name Perseverance following a nationwide K-12 student "name the rover" contest that attracted more than 28,000 proposals. A seventh-grade student, Alexander Mather from Lake Braddock Secondary School in Burke, Virginia, submitted the winning entry at the Jet Propulsion Laboratory. In addition to the honor of naming the rover, Mather and his family were invited to NASA's Kennedy Space Center to watch the rover's July 2020 launch from Cape Canaveral Air Force Station (CCAFS) in Florida.
Rank: 2 / Score: 0.9872
The Perseverance rover lifted off successfully on July 30, 2020, at 11:50:00 UTC aboard a United Launch Alliance Atlas V launch vehicle from Space Launch Complex 41, at Cape Canaveral Air Force Station (CCAFS) in Florida.
The reranking process returned content nodes that are highly relevant to the query. These nodes, which include detailed information about the Mars rover’s name, launch location, and date, were initially ranked lower, at positions 40 and 46, in the previous stage.
After reranking the content nodes, the top-k nodes are selected for every webpage for further processing. These nodes are concatenated with the webpage snippet to form a webpage document used in the next stage.
Stage 4: Information extraction
In this stage, each webpage document is processed by a LLM-based content extractor that uses a Llama3-8B model. The model is instructed to extract key information from a webpage document and create a concise summary. This removes unnecessary details, enabling the LLM in the subsequent response generation stage to focus on the essential information relevant to answer the query.
The following output shows the information extracted from the snippet and content nodes retrieved from https://en.wikipedia.org/wiki/Perseverance_(rover) in the previous stages:
1
Perseverance, nicknamed Percy, is a car-sized Mars rover designed to explore the Jezero crater on Mars as part of NASA's Mars 2020 mission. It was manufactured by the Jet Propulsion Laboratory and launched on July 30, 2020, at 11:50 UTC from Cape Canaveral Air Force Station (CCAFS) in Florida.
The name and launch date of the Mars rover is extracted from the webpage snippet, whereas the launch location is extracted from the rank-1 and rank-2 nodes retrieved in the previous stage.
Stage 5: Response generation
In the final stage of the pipeline a LLM (Llama3-8B) is instructed to generate a response to the query using only the webpage documents prepared in the previous stage. This approach is crucial as it restricts the LLM to the provided context, reducing tendencies to produce responses based on outdated or unsupported information (i.e. hallucinations).
The following shows the response of the search tool for our example query “What is the name of the latest NASA rover sent to Mars, when was it launched, and from which location?”
1
The latest NASA rover sent to Mars is the Perseverance rover, which was launched on July 30, 2020, at 11:50 UTC from Cape Canaveral Air Force Station (CCAFS) in Florida.
Usage and examples
The internet search tool requires a locally deployed instance of SearXNG and a Llama3-8B model served using llama.cpp. To get started, follow the setup instructions outlined here to setup SearXNG and here to install the required dependencies and serve the model (skip downloads for other mentioned models).
The SearchInternetTool is instantiated with the specified SearXNG endpoint, alongside the LLM and the reranker:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from sentence_transformers import CrossEncoder
from gba.client import Llama3Instruct, LlamaCppClient
from gba.tools.search.search_internet import SearchInternetTool
from gba.utils import Scratchpad
# locally deployed SearXNG instance
searxng_endpoint="http://localhost:8080"
# Proxy for 8-bit quantized Llama-3-8B-Instruct
llama3 = Llama3Instruct(llm=LlamaCppClient(url="http://localhost:8084/completion", temperature=-1))
# mxbai-rerank-large-v1 reranker
rerank_model = CrossEncoder("mixedbread-ai/mxbai-rerank-large-v1", device="cuda")
search_internet_tool = SearchInternetTool(
llm=llama3,
rerank_model=rerank_model,
searxng_endpoint=searxng_endpoint,
fetch_webpage_timeout=5.0,
top_k_documents=3,
top_k_nodes_per_document=5,
top_k_snippets=None,
)
To run the example query from the section Exploring the Internet Search RAG Pipeline use the internet_search_tool as illustrated below:
1
2
3
search_internet_tool.search(
query="What is the name of the latest NASA rover sent to Mars, when was it launched, and from which location?"
)
1
"The latest NASA rover sent to Mars is the Perseverance rover, which was launched on July 30, 2020, at 11:50 UTC from Cape Canaveral Air Force Station (CCAFS) in Florida."
Now that we know the name of the Mars rover let’s get some more information about it:
1
2
3
search_internet_tool.search(
query="How does the Perseverance rover's power system work, and what are its energy sources?"
)
1
"The Perseverance rover's power system works by converting heat generated from the natural decay of plutonium-238 into electricity using a multi-mission radioisotope thermoelectric generator (MMRTG), which produces about 110 watts of power, similar to a light bulb."
Now that we know the name of the Mars rover let’s get some more information about it:
1
2
3
search_internet_tool.search(
query="What is the current weather in vienna in celcius"
)
1
"The current weather in Vienna is 26°C."
The tool is also capable of processing more complex user requests:
1
2
3
search_internet_tool.search(
query="Search the internet for the movie that won the Best Picture Oscar in 2020 to find information about the number of Oscars it won and the categories of those awards."
)
1
"The movie "Parasite" won the Best Picture Oscar in 2020 and it won four awards, including Best Picture, Best Director, Best Original Screenplay, and Best International Feature Film."
Improvements
While the search tool generally performs well, there are several areas that could be improved in future work:
- Support for dynamic web pages: currently, the search tool is limited to loading static pages. Supporting dynamic web content that utilizes JavaScript would provide access to a broader spectrum of information.
- SearXNG search provider configuration: at present, the configuration of search providers is restricted to ensure reliable outputs. Expanding the number of search providers and sources would increase the diversity of the search results.
- Optimization of pipeline steps: the accuracy of individual search pipeline steps (query rewriting, content extraction, and response generation) could be improved by further refinement of the LLM prompts.
Conclusion
In this article, we discussed the capabilities and design of a RAG-based internet search tool that leverages the power of smaller, open-source Large Language Models like Llama3-8B. By integrating these models with the SearXNG metasearch engine, this tool addresses significant challenges in information retrieval using large language models - such as the issues of outdated information and hallucinations. The practical setup described not only ensures that the information retrieved is current and relevant to the intput query but also tailored to fit within the constraints of smaller models. Importantly, the entire system is designed to run locally, providing access to diverse internet sources without the complexities of external APIs.